Wer ein Synology NAS besitzt kann sich recht einfach einen eigenen Git-Server einrichten. Leider war die Anleitung zur Nutzung des Git-Servers für mich etwas irreführend, daher habe mir Infos zusammengesucht und beschreibe hier nochmal, wie man Git zusammen mit der Synology nutzen kann. Die meisten Infos habe ich von hier erhalten.
Installation
Um den Git-Server zu installieren, öffnet man in der DSM-Oberfläche als Admin das Paketzentrum und sucht nach Git. Beim Git-Server klickt man auf „Installieren“.
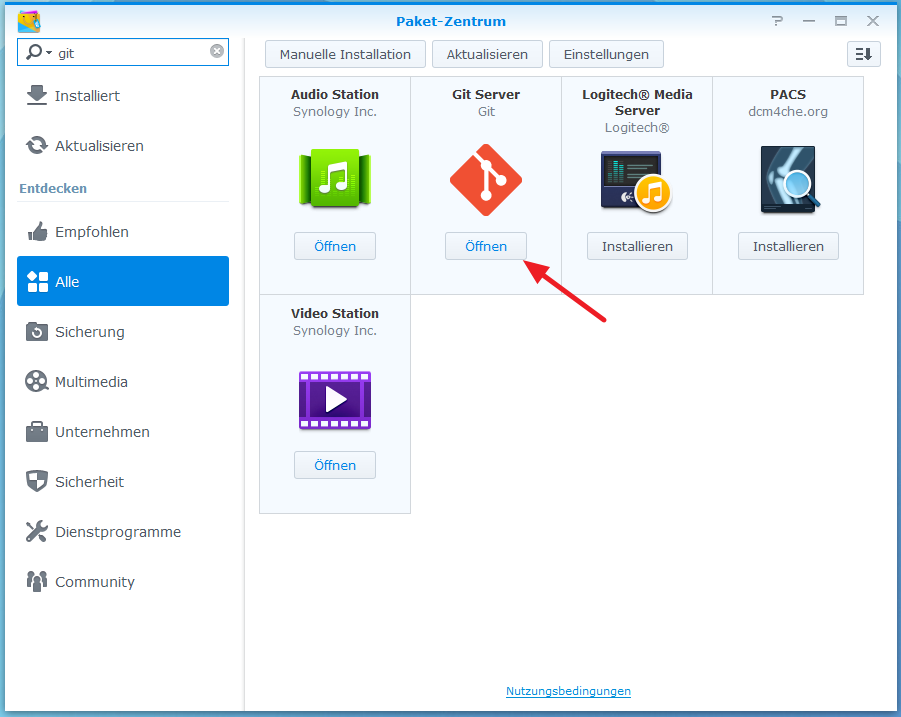
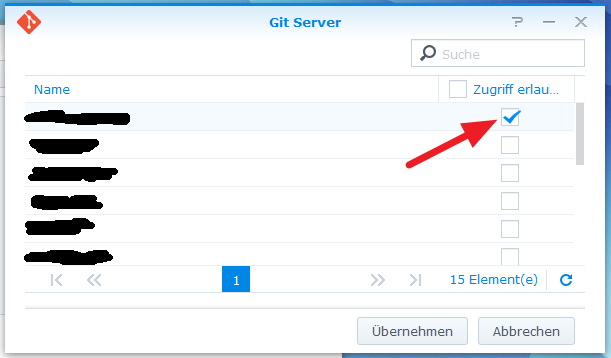
Falls nach dem Installieren nicht automatisch das folgende Fenster geöffnet wird, sucht man in der DSM-Oberfläche im Hauptmenü nach dem Git-Server und klickt das Symbol an. Es öffnet sich das folgende Fenster in dem man die User auswählt, die Zugriff über den Git-Server auf Git-Repositories auf der Synology erhalten sollen. Haken unter „Zugriff erlauben“ für den oder die Benutzer setzen und dann „Übernehmen“ auswählen.
Windows Dateidienst (und WebDAV) aktivieren
Falls noch nicht geschehen, aktiviert man den Windows Dateidienst. Die Git-Repositories werden direkt auf der Synology im Home-Verzeichnis des Synology-Benutzers angelegt, den man benutzt. Um sich die Arbeit zu vereinfachen kann man sich das Home-Verzeichnis des Synology-Benutzers auf seinem Client-Rechner einbinden. Dazu hat man verschiedene Möglichkeiten, ich habe den Windows-Dateidienst gewählt. Zum Aktivieren die Systemsteuerung starten und „Dateidienste“ auswählen.
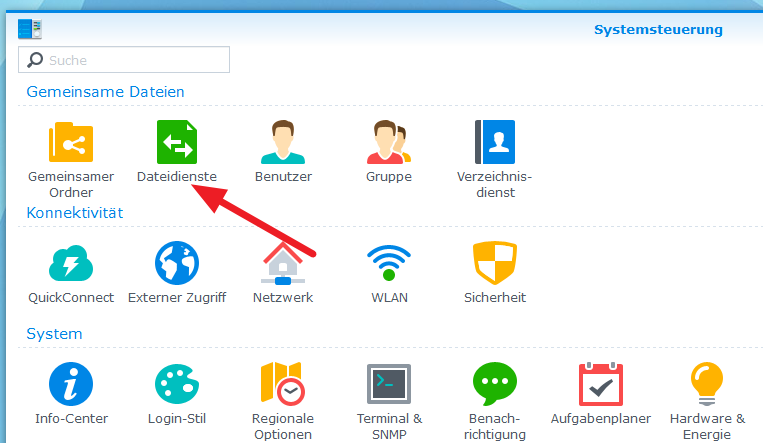
Dort nun einen Haken bei „Windows Dateidienst aktivieren“ setzen und auf „Übernehmen“ klicken.
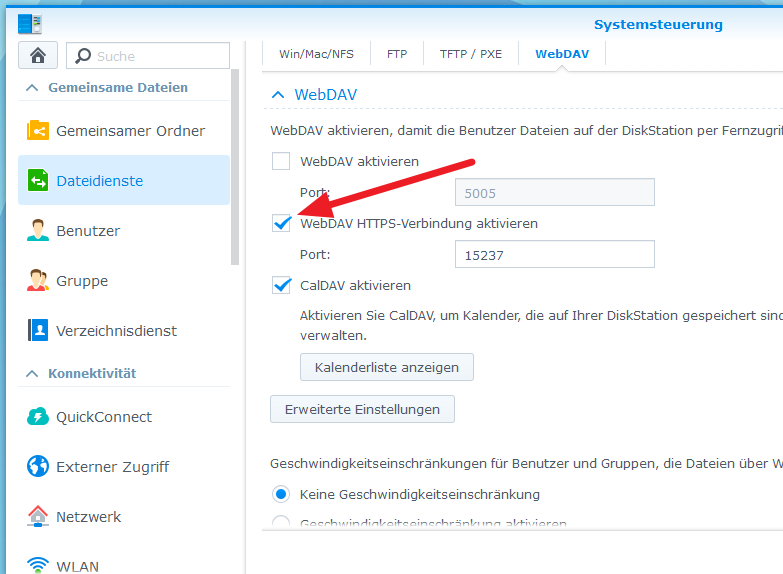
Für den Zugriff über Linux sollte man WebDAV aktivieren. Interessanterweise wurde mir mein home-Verzeichnis nicht angeboten, als ich unter Linux per SMB die Verbindung hergestellt habe. Daher noch auf den WebDAV Reiter wechseln und WebDAV aktivieren.
Git-Repository unter Windows anlegen
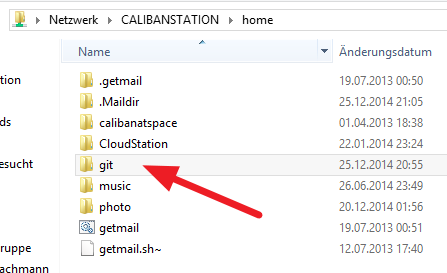
Bei mir ist meine Synology unter \\CalibanStation erreichbar. Um nun das Home-Verzeichnis nutzen zu können, öffnet man einen Windows-Explorer und gibt in der Adresszeile die Adresse der eigenen Synology in der Form \\Servername oder \\IP-Adresse ein. In meinem Fall \\CalibanStation. In der Ansicht sollte das „home“-Verzeichnis auftauchen. Das öffnet man nun und legt ein „git“ Verzeichnis an. Es sollte dann ähnlich wie im folgenden Screenshot aussehen:
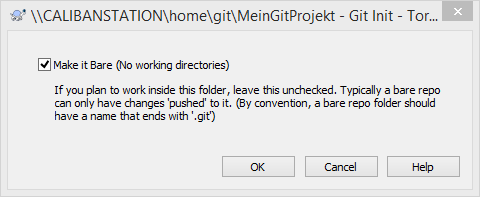
Für die weiteren Arbeiten benötigt man Git. Als Windows-Anwendung kann man dazu TortoiseGit nutzen, welches man hier herunterladen kann. Nachdem TortoiseGit installiert ist, wechselt man in das git-Verzeichnis auf dem geöffneten Synology-Home-Verzeichnis. Hier legt man nun ein neues Unterverzeichnis an, z.B. „MeinGitProjekt“ und wechselt in das neue Verzeichnis. Wenn man im Windows-Explorer nun die rechte Maustaste klickt, sollte im Kontextmenü ein Eintrag „Git Create Repository here…“ aufgeführt sein. Diesen anwählen. Nun wird man gefragt, ob man ein „Bare“ Repository anlegen will. Ein solches Repository ist für den Server gedacht und entsprechend aktivieren wir hier die Option. Dann mit „Ok“ generieren lassen.
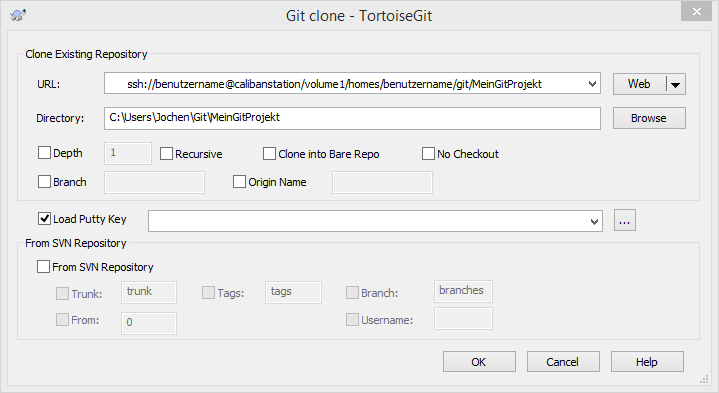
Ein neues Git-Repository ist damit auf dem Server angelegt. Eine Arbeitsversion kann man wie folgt auf den Client-Rechner auschecken.
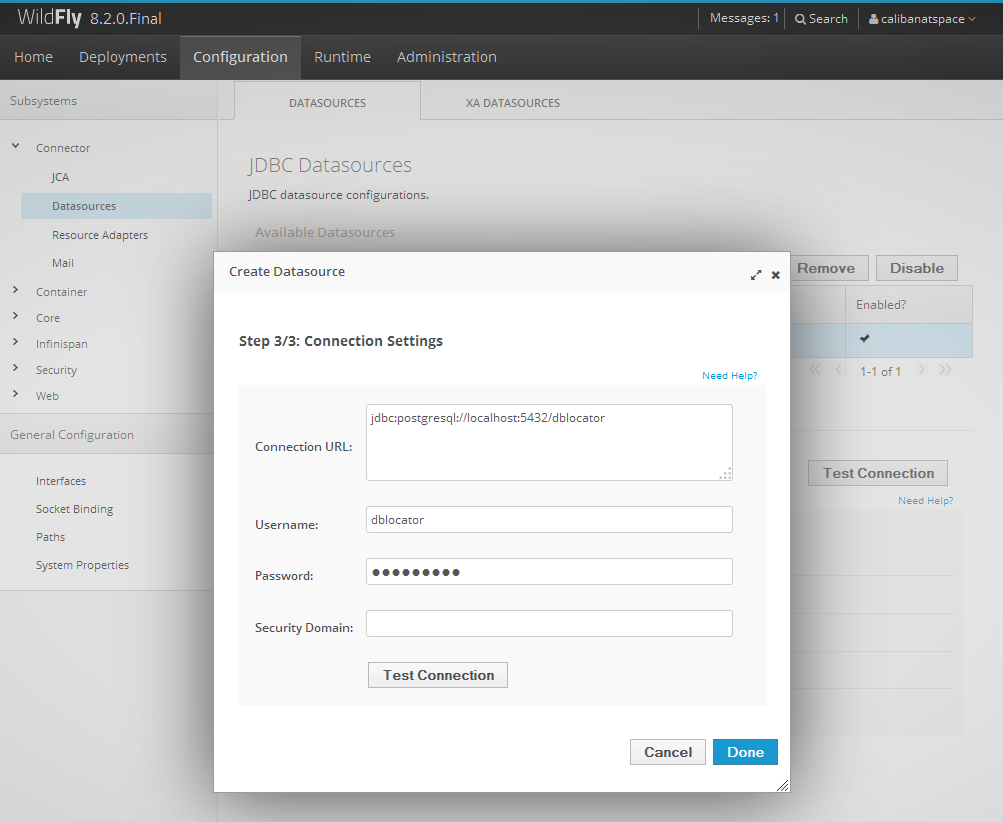
In seinem Arbeitsverzeichnis auf dem Client-Rechner betätigt man die rechte Maustaste und wählt im erscheinenden Kontextmenü den Eintrag „Git Clone…“ aus. Der Zugriff auf das Git-Repository „MeinGitProjekt“ erfolgt per SSH. Als URL gibt man folgendes ein, benutzername muss auf den eigenen Benutzernamen angepasst werden, calibanstation als Adresse für das eigenen Synology NAS anpassen und zu guter letzt noch MeinGitProjekt dem Namen des eigenen Git-Repositories auf dem NAS anpassen:
ssh://benutzername@calibanstation/volume1/homes/benutzername/git/MeinGitProjekt
Bei meinem Beispiel sehen die Daten in den Fenstern von TortoiseGit wie folgt aus:
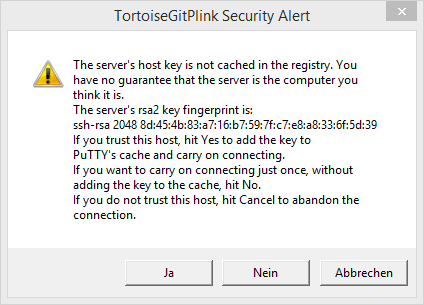
TortoiseGit meckert den ihm unbekannten Host Key an. Da ich meinem Synology NAS vertraue, bestätige ich die Abfrage mit „Ja“.
Nun werde ich nach dem Passwort des hier verwendeten Synology Benutzers benutzername gefragt. Eingeben und mit „Ok“ bestätigen, anschliessend wird das Git-Repository auf dem Client-Rechner ausgecheckt.
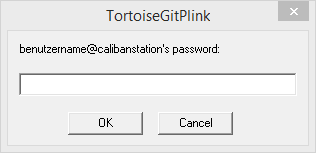
Fertig!
Git-Repository unter Ubuntu Linux 14.10 anlegen
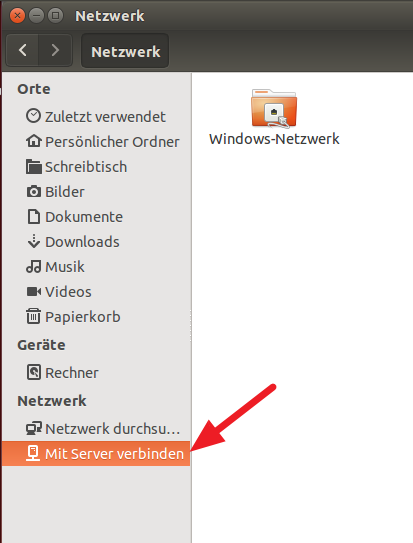
Unter Ubuntu benutze ich den Datei-Explorer. Im Datei-Explorer gibt es in der Seitenleiste einen Bereich „Netzwerk“. Dort sollte „Mit Server verbinden“ erscheinen. Den Eintrag auswählen. Falls der Eintrag nicht vorhanden ist, im Menü „Datei“ ist der Eintrag vorhanden.
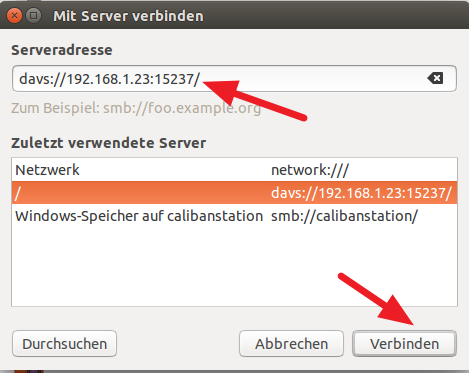
Ich nutze hier WebDAV (wie weiter oben schon erwähnt), da mein home-Verzeichnis bei SMB nicht mit angezeigt wurde. Als Serveradresse gibt man „smb://IP-Adresse:Port“ ein, in meinem Beispiel entsprechend „davs://192.168.1.23:15237/“. Auf „Verbinden“ klicken. Hat man Benutzernamen und Passwort noch nicht hinterlegt, wird man nun danach gefragt. Hier sind Benutzername und Passwort des entsprechenden Synology-Benutzers einzutragen.
Nun sollte man alle Verzeichnisse angezeigt bekommen, die man in der Synology auf seinen Benutzeraccount zugeordnet hat. Es sollte auch das home-Verzeichnis angezeigt werden. Für die weiteren Arbeiten wechseln wir jetzt auf ein Terminal. Im Terminal wechselt man in das gerade gemountete Verzeichnis, welches im Gnome Virtual File System zu finden ist:
cd /run/user/1000/gvfs/
Hier sollte jetzt das gemountete Verzeichnis zu sehen sein:
/run/user/1000/gvfs$ ll
insgesamt 0
dr-x------ 3 calibanatspace calibanatspace 0 Dez 24 23:15 ./
drwx------ 9 calibanatspace calibanatspace 260 Dez 24 23:15 ../
drwx------ 1 calibanatspace calibanatspace 0 Dez 20 01:56 dav:host=192.168.1.23,port=15237,ssl=true/
Wechseln in das gemountete Verzeichnis, inklusive Sprung direkt ins home-Verzeichnis:
cd dav\:host\=192.168.1.23\,port\=15237\,ssl\=true/home/
Falls noch nicht vorhanden, legt man hier ein Hauptverzeichnis für seine Git-Repositories an. Bei mir habe ich ein neues Verzeichnis „git“ angelegt, in dem alle weiteren Git-Repositories angelegt werden:
mkdir git
Um nun ein neues Git-Repository anzulegen, lege ich ein Unterverzeichnis unter dem git-Verzeichnis an und erzeuge ein bare-Git-Repository:
mkdir git/MeinGitProjekt
cd git/MeinGitProjekt
git --bare init
Das leere Git-Repository kann nun in einem anderen Verzeichnis geclont werden. benutzername, IP-Adresse und Repositoryname sind entsprechend anzupassen.
cd ~/git
git clone ssh://benutzername@192.168.1.23/volume1/homes/benutzername/git/MeinGitProjekt